Prefect Fugue Integration



![]()
![]()
![]()
This project provides the Fugue tasks, context and blocks for Prefect.
Getting Started
Fugue is a unified interface for distributed computing that lets users execute Python, pandas, and SQL code on Spark, Dask and Ray without rewrites.
The most common use cases are:
- Accelerating or scaling existing Python and pandas code by bringing it to Spark or Dask with minimal rewrites. Using FugueSQL to define end-to-end workflows on top of pandas, Spark, and Dask DataFrames. FugueSQL is an enhanced SQL interface that can invoke Python code with added keywords.
- Maintaining one codebase for pandas, Spark, Dask and Ray projects. Logic and execution are decoupled through Fugue, enabling users to be focused on their business logic rather than writing framework-specific code.
- Improving iteration speed of big data projects. Fugue seamlessly scales execution to big data after local development and testing. By removing PySpark code, unit tests can be written in Python or pandas and ran locally without spinning up a cluster.
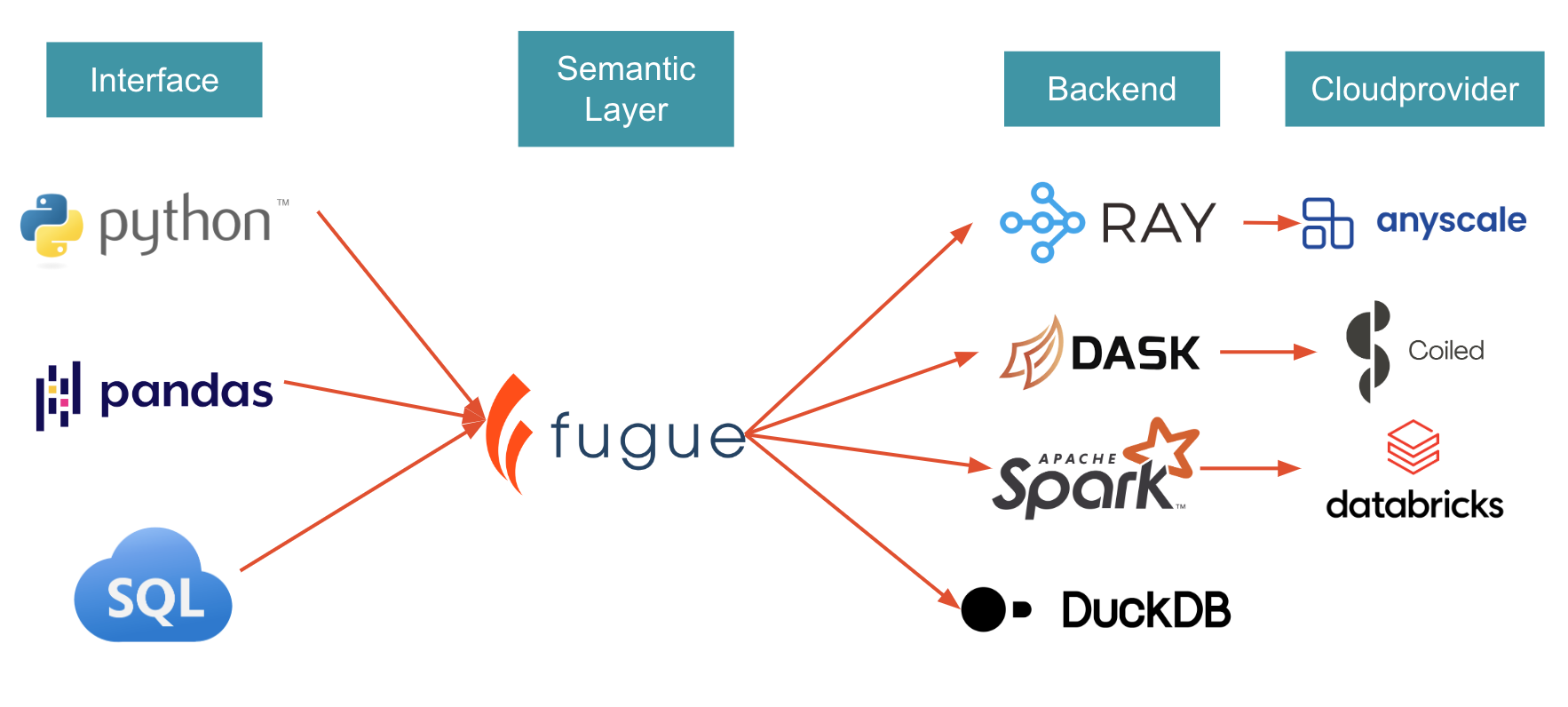
The best way to get started with Fugue is to work through the 10 minute tutorials:
Python setup
Requires an installation of Python 3.7+.
We recommend using a Python virtual environment manager such as pipenv, conda or virtualenv.
These tasks are designed to work with Prefect 2.0. For more information about how to use Prefect, please refer to the Prefect documentation.
Installation
Install prefect-fugue with pip:
pip install prefect-fugue
It's also recommended to register Fugue blocks into your current Prefect workspace:
prefect block register -m prefect_fugue
Creating a Block
This will allow a creation of the Fugue Engine block
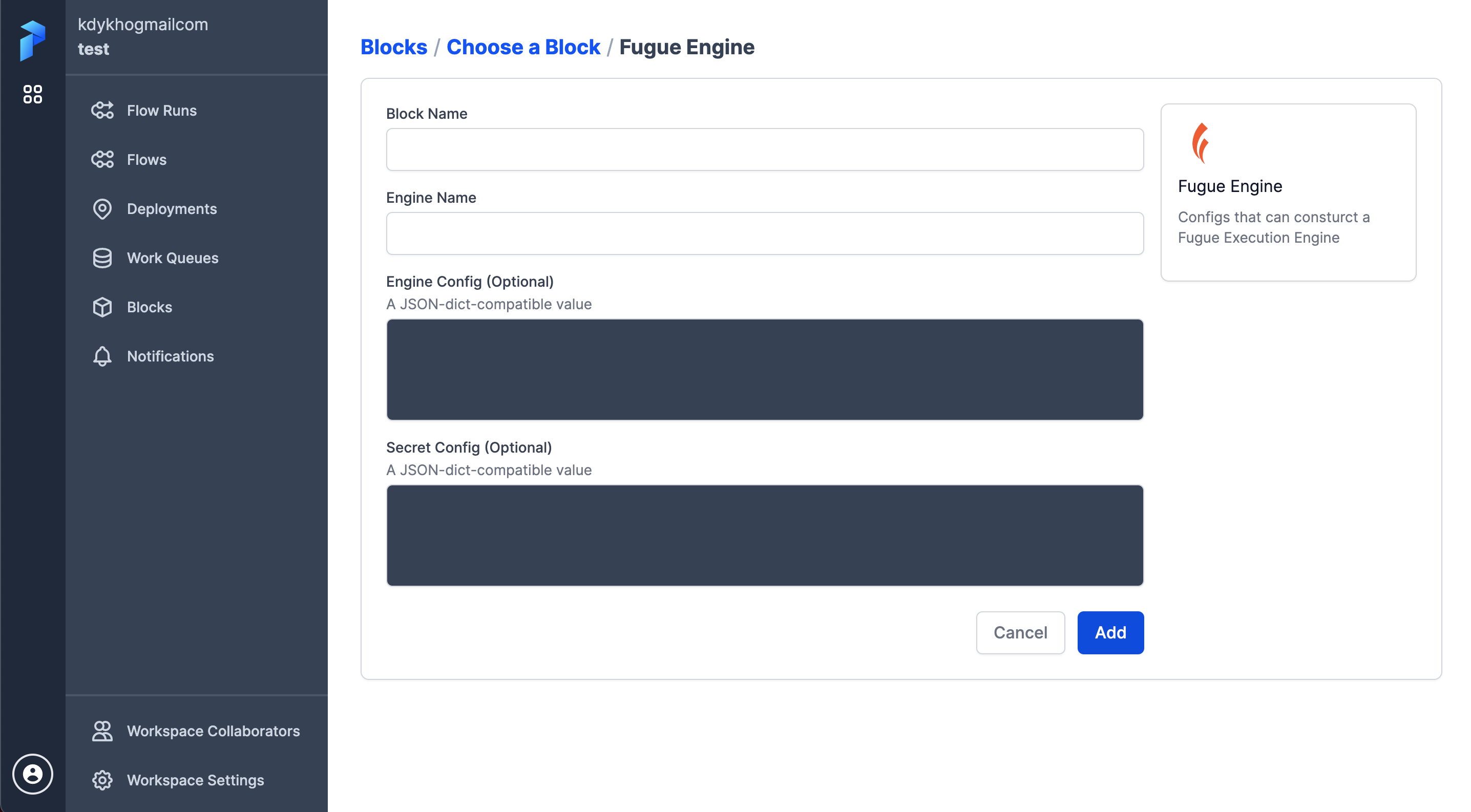
There are 4 items that need to be filled to create a block.
- Block Name - name that will be used to use the block.
- Engine Name - one of the Fugue supported backends (spark, dask, ray, duckdb)
- Engine Config - configurations related to the cluster
- Secret Config - credentials to connect to a cluster
For example, a Databricks Block could look like:
- Block Name - databricks
- Engine Name - spark
- Engine Config - None
- Secret Config - seen below
{
"host": "https://dbc-38aaa459-faaf.cloud.databricks.com",
"token": "dapiecaaae64a727498daaaaafe1bace968a",
"cluster_id": "0612-191111-6fopaaaa"
}
Using a Spark Cluster Inside a Flow
Let’s start by running code on top of Databricks. databricks-connect is already installed in this environment. This section may have a lot of logs because of the monitoring provided by Prefect. This section also assumes that the user has Prefect configured to the right workspace.
Below we have one task that takes in a SparkSession and uses it to run some Spark code. We can then use this in the Prefect Flow with the fugue_engine context. This fugue_engine will create an ephemeral cluster to run the code underneath, and then turn off when finished.
from prefect import task, flow
from prefect_fugue import fugue_engine
@task
def my_spark_task(spark, n=1):
df = spark.createDataFrame([[f"hello spark {n}"]], "a string")
df.show()
@flow
def native_spark_flow(engine):
with fugue_engine(engine) as engine:
my_spark_task(engine.spark_session, 1)
native_spark_flow("fugue/databricks")
Similarly, if you don’t use Databricks but have your own way to get a SparkSession, you can directly pass the SparkSession into the Flow. The fugue_engine context will be able to interpret this.
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
native_spark_flow(spark)
Testing Locally Before Running Map Jobs on Spark, Dask, and Ray
We showed how to run Spark code on top of a Spark cluster, but the strength of Fugue is decoupling from distributed framework code such as Spark and Dask. Decoupling from these frameworks allows us to test code locally before scaling out to a cluster. In the example below, we simulate having a pandas DataFrame where each row is a job.
When testing the Flow, we can pass None as the engine so everything runs on Pandas. When ready to scale out, we can pass in our Block or SparkSession. Fugue’s transform() task will use the engine provided by the fugue_engine context.
from time import sleep
import pandas as pd
from prefect_fugue import transform
@task
def create_jobs(n) -> pd.DataFrame:
return pd.DataFrame(dict(jobs=range(n)))
# schema: *,batch_size:str
def run_one_job(df:pd.DataFrame) -> pd.DataFrame:
sleep(len(df)*5)
return df.assign(batch_size=len(df))
@flow
def run_all_jobs(n, engine=None):
jobs = create_jobs(n)
with fugue_engine(engine):
return transform(jobs, run_one_job, partition="per_row", as_local=True)
We can test the Flow above on a local machine without Spark. We run on one job first.
run_all_jobs(1) # run locally on Pandas
Becasue it succeeded, we can now attach our Fugue Databricks Block to run on Databricks. Now we run on 8 jobs, and we’ll see that parallelization from the Spark cluster will make this Flow execute faster.
run_all_jobs(8, "fugue/databricks") # run on databricks
There is still some overhead with sending the work, but the time is decreased compared to the expected execution time if ran sequentially (40 seconds).
We can also use local Dask by passing the string "dask". We can also pass a Dask Client() or use the Fugue Engine Block with Coiled. More information can be found in the Coiled cloudprovider docs.
run_all_jobs(4, "dask")
Running SQL on any Spark, Dask, and Duckdb
Prototyping locally, and then running the full job on the cluster is also possible with FugueSQL. DuckDB is a good engine to run SQL queries on flat files or Pandas DataFrames. When ready, we can bring it to SparkSQL on the cluster. Similar to the transform() task shown above, there is also an fsql() task.
Here we can load in data and perform a query with FugueSQL. FugueSQL has additional keywords such as LOAD and SAVE so we can run everything from loading, processing, and saving all on DuckDB or SparkSQL. More information on FugueSQL can be found in the FugueSQL tutorials.
@flow
def run_sql_full(top, engine):
with fugue_engine(engine):
fsql("""
df = LOAD "https://d37ci6vzurychx.cloudfront.net/trip-data/green_tripdata_2022-01.parquet"
SELECT PULocationID, COUNT(*) AS ct FROM df
GROUP BY 1 ORDER BY 2 DESC LIMIT {{top}}
PRINT
""", top=top)
To debug locally without SparkSQL, we can use DuckDB as the engine.
run_sql(2, "duckdb"); # debug/develop without spark
Again to run on the cluster, we can use the Databricks Block.
run_sql(10, "fugue/databricks")
Resources
If you encounter any bugs while using prefect-fugue, feel free to open an issue in the prefect-fugue repository.
If you have any questions or issues while using prefect-fugue, you can find help in the Fugue Slack community.
Development
If you'd like to install a version of prefect-fugue for development, clone the repository and perform an editable install with pip:
git clone https://github.com/fugue-project/prefect-fugue.git
cd prefect-fugue/
pip install -e ".[dev]"
# Install linting pre-commit hooks
pre-commit install